
Aaksha Meghawat, Chris Bogart, Carolyn P. Rose
In 2016, I started out with the goal of using natural language processing & discourse analysis to improve developer productivity on Github. Thanks to early success in our computational approaches, we were soon asking the question of whether we could predict if an open source project was on the path to failure or success. This was further motivated by the fact that a developer’s time is limited and therefore in Open Source communities, they need to make important decisions regarding which projects to depend upon as resources and which projects to contribute towards.
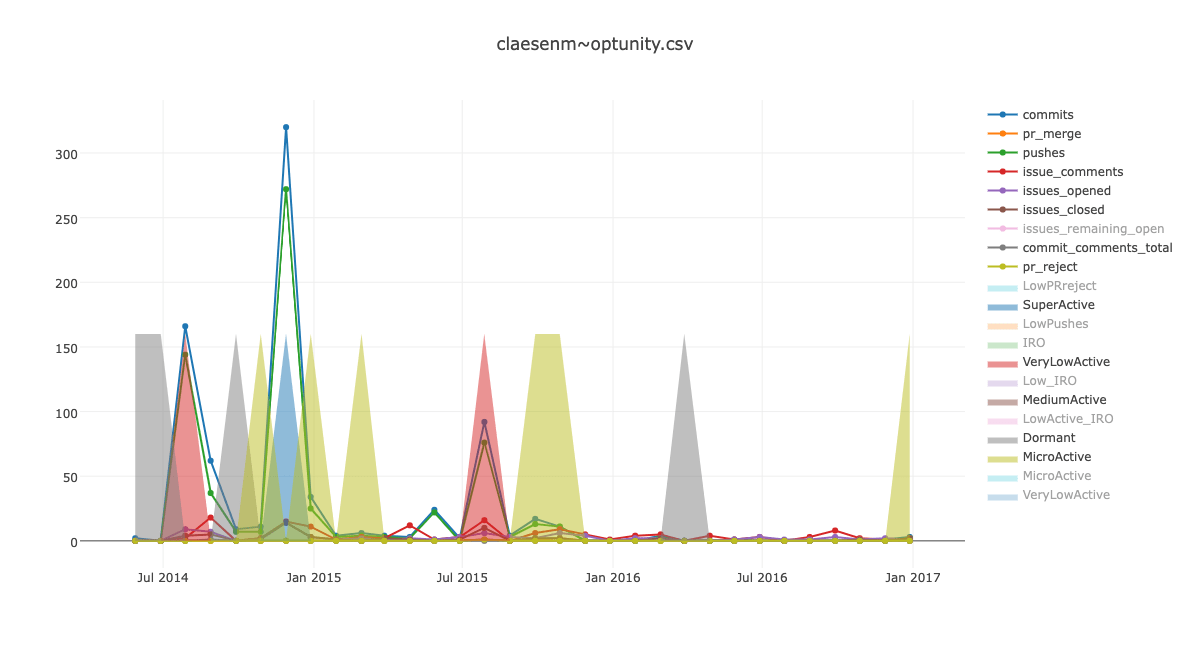
Our qualitative analysis to develop computational measures for conversational quality revealed that projects went through different phases of activity (Fig. 1). First, to help in characterization of the ‘activity’ phases, we collected several important activity parameters such as commits, pull request merges, pushes, issue comments, issues opened, issues closed, commit comments, pull request rejections and issues remaining open totaled per month of a project’s timeline on Github.

Next, we needed a model that would be able to detect these phases of a project assigning a clear phase identifier for the months of activity of the projects. This identification would make the wide variety of projects comparable at different points in time. For example, this would help in comparing the coordination style of a new small-sized project in a phase with an older project’s earlier days when it had been a small-sized project and was in the same activity phase.
“One can think of this as a health checkup of the open source project. The activity indicators are like the vital stats of the project. This combined with its history when compared to life histories of other successful or unsuccessful open source projects can give some early indication of its potential “health” problems and survival rate”.
We hoped that enabling such comparisons would drive insight as to the quality of coordination that may have helped a project in surviving long enough to attract more resources and become a big project. A clear interpretation of these states in terms of the parameters collected would help in evaluating the soundness of the model’s states. Further, our understanding of how the phases progressed and what kind of coordination and conversation would result in a project reaching favorable or unfavorable stages in their life cycles would improve. For this reason, we decided to apply models that would infer discrete states for the project timelines.
The other important characteristic of the project timelines that we discovered in our preliminary qualitative analysis was that developers worked in bursts of activity. This clearly meant that the activity (and phase) in one month was not un-correlated with the previous month’s activity in the sequence of months that formed the timeline of a project. We needed a model that would consider the temporal dependence of the activities reflecting the fact that some activity in one time unit increases the probability of seeing more activity in the next time unit. At the minimum, we needed a model that would relax the i.i.d. assumption for its data points (time units of months in our case).
We conceptualized that the discrete state would be an indicator of the phase of the project’s lifecycle which would be expressed via the activity visible on the platform. The project’s current state would determine the state that it would occupy in the next time unit. Since the phase of a project was not visible and was not specified directly on Github, our statistical model would have to infer the hidden state from the visible activity snapshots and learn a probabilistic distribution over these activity variables to better fit and account for the variety of activity that happens on the platform.
The Hidden Markov Model (HMM) fit all these requirements neatly. The markov property of the model captured the intuition that the present state determined the future state of a project. The HMM is a statistical Markov model in which the system being modeled is assumed to be a Markov process with unobserved (i.e. hidden) states. Additionally, we chose to model the probabilistic relation between the discrete states and the activity on the platform via a multivariate Gaussian distribution. This way we could leverage the flexibility of a probabilistic fit on the observed activity to acquire a better model. At the same time we could take advantage of the interpretability of the Gaussian distribution by understanding every discrete state that the model inferred in terms of the mean value of the observed activity parameters.
Data Collection
We attempted to achieve the fine balance between having homogeneous samples in terms of the type of projects and them being diverse enough in terms of work coordination. For this reason we chose a single domain of development, Pypi projects and began with a large set of projects within this domain in Github. We began with a list of 48,668 github repositories mentioned in PyPi metadata records. From these we altered for projects having at least 10 stars or 3 contributors. We took stars and contributors as an approximation of the community’s interest in the project, leaving us with 16,682 projects.
There were discrepancies in many projects because of projects whose names had changed or for which data was missing or deleted from one data source or another. As we were looking at fine-grained interactions over short timespans, we wanted a particularly clean set of projects. We finally had 13,479 pypi projects in our set.
We trained a multivariate Gaussian hidden Markov Model (HMM) on these activity parameters. For the month level HMM, 12 discrete states provided the best fit on the activity time lines of a held out set of projects. We then included all the months that were labeled for discrete states of the Gaussian HMM which showed significant levels of activity. We focused our analysis on 6 states with significant transition probabilities (Figure 2). After filtering for the active months, only 4934 projects remained in our set as of the 13479 projects that we started with, only these many had active months.

Interpretation
The transition probabilities of the HMM states confirmed most of our qualitative conclusions of the activity patterns of projects. Any project was most likely to start and stay in the dormant state. Furthermore a project’s probability to maintain its current state, whether dormant or active was higher than transitioning to a different state. The trend of staying in the dormant state created the issue of data sparsity. The trend of staying in the active state created the phenomenon of bursts. Both these intuitions are visible in the HMM model.
It may be argued that one could set a low threshold on the activity parameters to capture most activity. However, in our qualitative study we found that low activity which preceded or followed high active states was also crucial in determining the coordination quality during that burst. All low activity is not important however and can be ignored to avoid noise. A markov model can automatically take care of such subtleties.
Future Work
This HMM lifecycle framework has already been used as a filtering mechanism to focus on different phases of a project by other researchers. This helps them zero in on the phases of a project they are most interested in to observe or measure other metrics relevant to their problem statement.
Potential future work also includes gaining a better understanding of the kinds of events/factors that cause the project to transition from one state to another, eventually estimating their survival rate.
Leave a Reply